

声享正努力加载中...
HTTP中的编码和解码
庞博文
前言
准备了很久的,PPT在老牛忙的提醒下发现居然有小伙伴讲过了,赶紧删删删,发现居然不剩下什么了,心塞ing,来组肇事人无码高清大图

请选取图片区域

请选取图片区域
内心一下想到了下面的图片
本来写这篇也是在工作中遇到了编解码相关的问题,被大佬批评教育了一凡,干脆直接讲编解码好了~

请选取图片区域

请选取图片区域

请选取图片区域
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。 HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1。
2014年12月,互联网工程任务组(IETF)的Hypertext Transfer Protocol Bis(httpbis)工作小组将HTTP/2标准提议递交至IESG进行讨论,于2015年2月17日被批准。 HTTP/2标准于2015年5月以RFC 7540正式发表,取代HTTP 1.1成为HTTP的实现标准。
HTTP协议
HTTP协议概述
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
TCP/IP
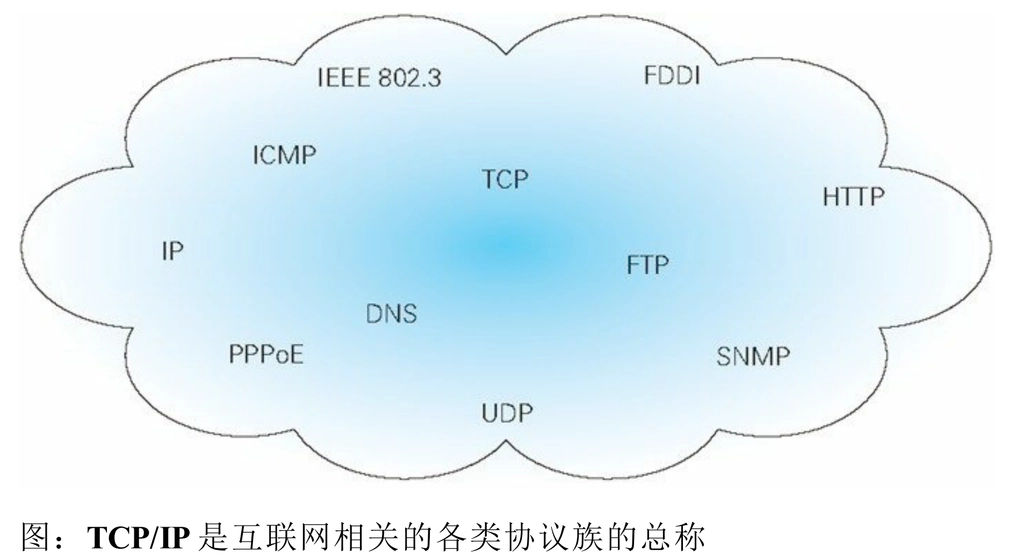
通常使用的网络(包括互联网)是在 TCP/IP 协议族的基础上运作的。而 HTTP 属于它内部的一个子集。
计算机与网络设备要相互通信,双方就必须基于相同的方法。比如,如何探测到通信目标、由哪一边先发起通信、使用哪种语言进行通信、怎样结束通信等规则都需要事先确定。不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则。而我们就把这种规则称为协议(protocol)。
请选取图片区域
协议中存在各式各样的内容。从电缆的规格到 IP 地址的选定方法、 寻找异地用户的方法、双方建立通信的顺序,以及 Web 页面显示需 要处理的步骤,等等。 像这样把与互联网相关联的协议集合起来总称为 TCP/IP。也有说法 认为,TCP/IP 是指 TCP 和 IP 这两种协议。还有一种说法认为,TCP/ IP 是在 IP 协议的通信过程中,使用到的协议族的统称。
TCP/IP 的分层管理
TCP/IP 协议族里重要的一点就是分层。TCP/IP 协议族按层次分别分为以下 4 层:应用层、传输层、网络层和数据链路层。 把 TCP/IP 层次化是有好处的。比如,如果互联网只由一个协议统筹,某个地方需要改变设计时,就必须把所有部分整体替换掉。而分层之后只需把变动的层替换掉即可。把各层之间的接口部分规划好之后,每个层次内部的设计就能够自由改动了。 值得一提的是,层次化之后,设计也变得相对简单了。处于应用层上的应用可以只考虑分派给自己的任务,而不需要弄清对方在地球上哪个地方、对方的传输路线是怎样的、是否能确保传输送达等问题。
TCP/IP 协议族各层的作用如下。
应用层
应用层决定了向用户提供应用服务时通信的活动。 TCP/IP 协议族内预存了各类通用的应用服务。比如,FTP(File Transfer Protocol,文件传输协议)和 DNS(Domain Name System,域名系统)服务就是其中两类。 HTTP 协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。 在传输层有两个性质不同的协议:TCP(Transmission Control Protocol,传输控制协议)和 UDP(User Data Protocol,用户数据报协议)。
网络层(又名网络互连层)
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数 据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计 算机,并把数据包传送给对方。 与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所 起的作用就是在众多的选项内选择一条传输路线。
链路层(又名数据链路层,网络接口层)
用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
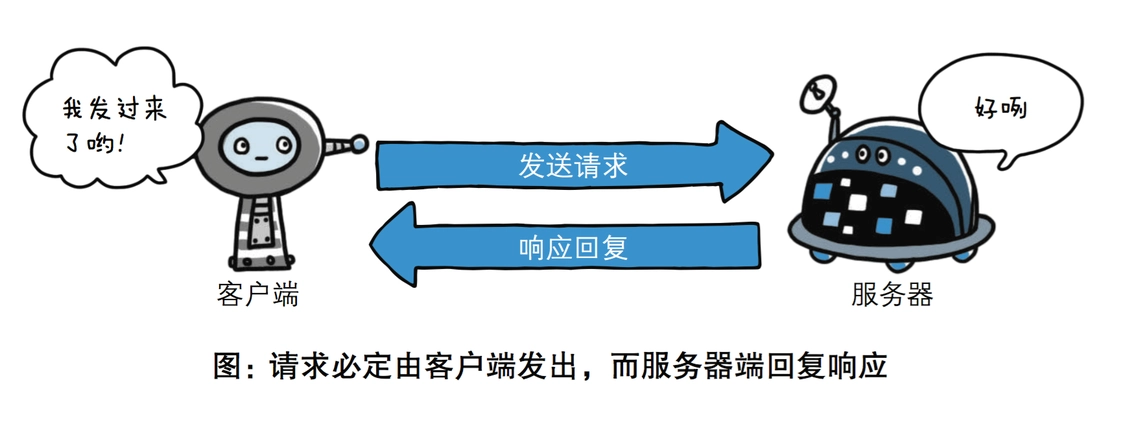
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
请选取图片区域
字符集与文字编码简介
1. 计算机如何显示文字
我们知道,计算机是以二进制的“形式”来保存和处理数据的,也就是说,不管我们使用键盘进行输入,还是让计算机去读取一个文本文件,计算机得到的原始内容是一些二进制序列,当需要对这些二进制序列进行显示时,计算机会依照某种“翻译机制”(也就是编码方式),取到这些二进制序列所表示的每个文字的“轮廓描述”(点阵或者矢量图),知道了轮廓,计算机便可以将二进制序列所表示的实际的文字形状显示到屏幕上了,这里面的思想和用学号来表示一个学生是一样的。(当然,这里面具体的知识点会很多,相关知识可以参考《计算机图形学》中显示原理的部分和其他与计算机显示原理相关的基础书籍)。
2. 字符集
将一些自然语言中的字符组成一个集合,并对集合中的每个字符制定规范化的编码方式,这个字符的集合和规范化的编码方式就组成了一个字符集。如ASCII字符集里面包括了所有的英文字母,并且指定了这些英文字母的编码规则。GB2312字符集里面包括了常用的简体汉字,并且指定了这些简体汉字的编码规则。
3. 字符编码
字符编码,就是建立一套自然语言中的“字符”跟计算机能够存储 处理的二进制数的映射的规则,即在一个字符集内,用一个特定的二进制数表示一个唯一“字符”,类似于学号跟学生的映射关系。为了保证统一性,兼容性,国际上会对“字符”和“内码”的映射关系指定标准,这样就有了ASCII、Unicode等标准的编码方式,详细的编码方式请参考字符编码和其他相关资料。
二、泛意义上的编码和解码
1. 为什么需要编码
当数据不利于处理、存储的时候,就需要对它们进行编码。如对字符进行编码是因为自然语言中的字符不利于计算机处理和存储。对图片信息、视频信息、声音信息进行压缩、优化,将其“格式化”,是为了在保证媒体资源质量的同时,尽量的节省网络带宽和本地存储的空间。对URL进行编码,是为了避免URL解析发生歧义,简化解码方式,如:URL采用“&”作为不同参数的分隔符,假如某个特定的参数的名称或者值本身就包括分隔符“&”,如果不将参数中的“&”做编码转换,那势必会增加URL解析的复杂性,提高解析错误的概率。
2.什么情况下使用编码
http协议中参数的传输是"key=value"这种简直对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?name1=value1&name2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出参数值,在计算机中使用用ASCII码表示如果我的参数值中就包含=或&这种特殊字符的时候该怎么办。 比如说“name1=value1”,其中value1的值是“va&lu=e1”字符串,那么实际在传输过程中就会变成这样“name1=va&lu=e1”。我们的本意是就只有一个键值对,但是服务端会解析成两个键值对,这样就产生了歧义。
URL编码只是简单的在特殊字符的各个字节前加上%,例如,我们对上述会产生奇异的字符进行URL编码后结果:“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。 例如,Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc&ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和=符号进行转义,也就是对其进行编码。 又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。 Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
3.哪些字符需要编码
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。 US-ASCII字符集中没有对应的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。 保留字符:Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ] 不安全字符:还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。 空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用 #:通常用于表示书签或者锚点 %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码 {}|\^[]`~:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*'()还有保留字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。 但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于~符号,虽然RFC3986文档规定,对于波浪符号~,不需要进行Url编码,但是还是有很多老的网关或者传输代理会进行编码。
4. 怎么样进行编码和解码
根据实际需求的差异,编码、解码算法有可能会很复杂,也有可能非常的简单,但是从根本上来讲,编码、解码只是在做翻译工作,将一种形式的数据翻译为另一种形式的数据,如,最简单的编码、解码就是相当于从一个Map中根据key查找value,然后使用value代替实际数据中的key的值。复杂一点儿的编码如javascript中的encodeURIComponent和decodeURIComponent,encodeURIComponent负责将字符串中不符合URL编码规范的字符转换为“%”形式的十六进制Unicode内码序列,decodeURIComponent负责将“%”形式的十六进制Unicode内码序列转换为实际的字符。
三、HTTP协议中的编码和解码
1. URL的编码和解码
decodeURI
encodeURI
encodeURIComponent
decodeURIComponent
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/encodeURIComponent
escape
unescape
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/escape
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/unescape
已废弃的编解码
Javascript中的escape, encodeURI和encodeURIComponent的区别
下面列出了这三个函数的安全字符(即函数不会对这些字符进行编码) escape:*/@+-._0-9a-zA-Z
encodeURI:!#$&'()*+,/:;=?@-._~0-9a-zA-Z encodeURIComponent:!'()*-._~0-9a-zA-Z
兼容性不同:escape函数是从Javascript 1.0的时候就存在了,其他两个函数是在Javascript 1.5才引入的。但是由于Javascript 1.5已经非常普及了,所以实际上使用encodeURI和encodeURIComponent并不会有什么兼容性问题。
对Unicode字符的编码方式不同:
这三个函数对于ASCII字符的编码方式相同,均是使用百分号+两位十六进制字符来表示。但是对于Unicode字符,escape的编码方式是%uxxxx,其中的xxxx是用来表示unicode字符的4位十六进制字符。这种方式已经被W3C废弃了。但是在ECMA-262标准中仍然保留着escape的这种编码语法。encodeURI和encodeURIComponent则使用UTF-8对非ASCII字符进行编码,然后再进行百分号编码。这是RFC推荐的。因此建议尽可能的使用这两个函数替代escape进行编码。
适用场合不同:
encodeURI被用作对一个完整的URI进行编码而encodeURIComponent被用作对URI的一个组件进行编码。
从上面提到的安全字符范围表格来看,我们会发现,encodeURIComponent编码的字符范围要比encodeURI的大。
我们上面提到过,保留字符一般是用来分隔URI组件(一个URI可以被切割成多个组件,参考预备知识一节)或者子组件(如URI中查询参数的分隔符),如:号用于分隔scheme和主机,?号用于分隔主机和路径。由于encodeURI操纵的对象是一个完整的的URI,这些字符在URI中本来就有特殊用途,因此这些保留字符不会被encodeURI编码,否则意义就变了。
组件内部有自己的数据表示格式,但是这些数据内部不能包含有分隔组件的保留字符,否则就会导致整个URI中组件的分隔混乱。因此对于单个组件使用encodeURIComponent,需要编码的字符就更多了
首先,由于URL是采用ASCII字符集进行编码的,所以如果URL中含有非ASCII字符集中的字符,那就需要对其进行编码。再者,由于URL中好多字符是保留字,他们在URL中具有特殊的含义。如“&”表示参数分隔符,如果想要在URL中使用这些保留字,那就得对他们进行编码。
根据2005年发布的RFC3986“%编码”规范:对URL中属于ASCII字符集的非保留字不做编码;对URL中的保留字需要取其ASCII内码,然后加上“%”前缀将该字符进行替换(编码);对于URL中的非ASCII字符需要取其Unicode内码,然后加上“%”前缀将该字符进行替换(编码)。由于这种编码是采用“%”加上字符内码的方式,所以,有些地方也称其为“百分号编码”。
虽然“百分号编码”对URL的编码方式做了详细的规定,但是实践中,浏览器对于URL的编码方式还是存在一些差异(主要表现在对非ASCII字符编码的差异),接下来我们首先展示不同浏览器(chrome和IE)对URL编码 的差异性,然后再对这些差异性做一些客观的总结和分析。
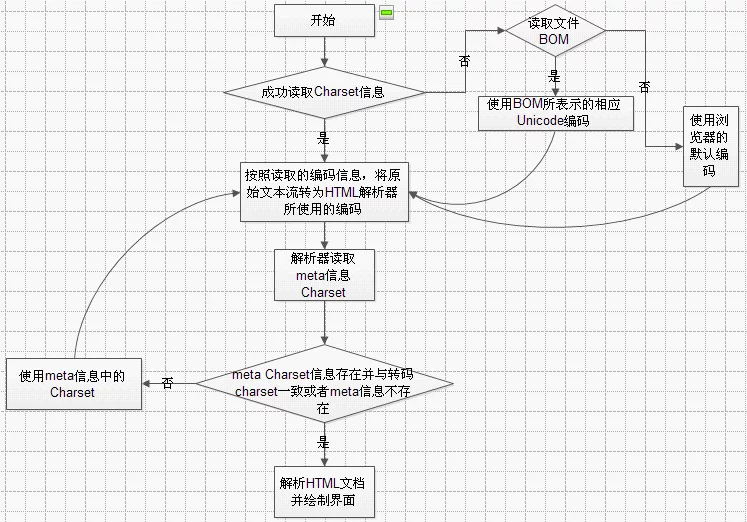
浏览器对于HTML文档的解码流程
请选取图片区域
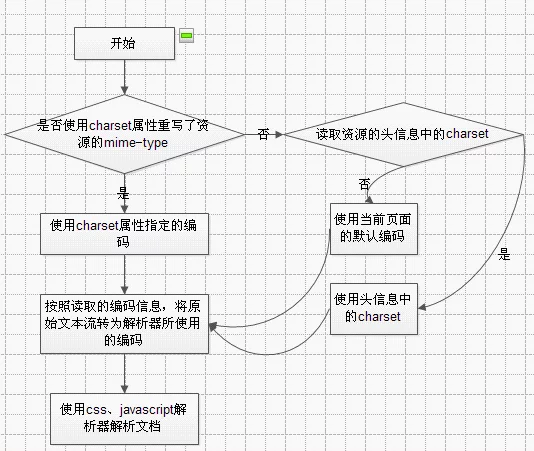
浏览器对于CSS/JS文档的解码流程
请选取图片区域
请选取图片区域
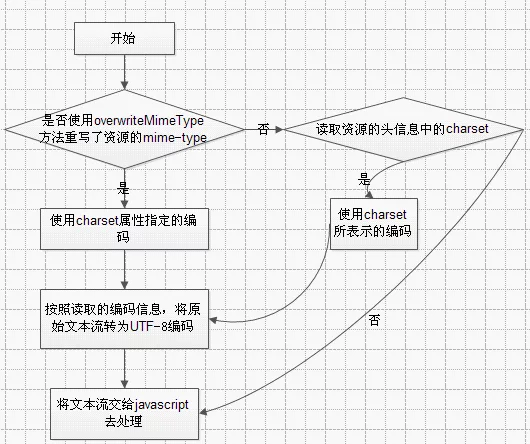
AJAX请求中,浏览器对“数据”的解码流程





设计模式-工程模式
2021-02-24 13
Http协议
2021-01-14 10
解析,语法抽象树及最小化解析时间的 5 条小技巧
2019-12-25 25
